
Seit Frühjahr 2020 greifen dpa-Kunden mit ihrer dpa ID auf die Text-to-Speech-Anwendung BotTalk zu. Das Hamburger Start-up wandelt geschriebene Nachrichtenartikel auf Knopfdruck in Audiodateien um und macht so Leser zu Zuhörern. In einem Gastbeitrag schildert Andrey Esaulov, CEO und Co-Founder, den erfolgreichen Karriereweg der jungen Firma und beleuchtet zentrale Fragen zum Thema Text-to-Speech, die sich für Medienhäuser stellen.
Ein Gastbeitrag von Andrey Esaulov
BotTalk ist eine Text-to-Speech-Software-Plattform, die wir speziell für Publisher von Nachrichten entwickelt haben. Viele Medienhäuser setzen BotTalk heute schon erfolgreich ein und „audifizieren“ täglich mehrere hundert Artikel auf Knopfdruck (darunter die Neue Osnabrücker Zeitung, der Weser-Kurier oder die Augsburger Allgemeine).
Bei der Entwicklung unserer Software konnten wir von der Unterstützung des Start-up-Ökosystems in Deutschland profitieren, das das „Innovations-Zusammenspiel“ von Medien-Startups und Medienunternehmen erleichtert. Nachdem wir unser Potenzial im Inkubator MEDIA LIFT von nextMedia.Hamburg unter Beweis stellen durften, wurden wir vom next media accelerator (NMA) entdeckt. Der 2015 von der dpa initiierte NMA hat mittlerweile in über 70 Gründerteams aus fast 20 Ländern investiert.
Seit einem Jahr sind wird nun auch Teil des dpa-Marktplatzes. Die Nachrichtenagentur bietet Start-ups mit einem ausgereiften Produkt die Möglichkeit, sich direkt hunderten von dpa-Kunden in der Medien- und Kommunikationsbranche vorzustellen. BotTalk ist über die dpa ID und einen „App Switcher“ nur einen Klick von den Services der dpa und ihrer Partner entfernt. Durch diese Partnerschaft konnten wir schon viele Verlage erreichen – und wertvolles Feedback einsammeln, das unser Produkt noch besser gemacht hat.
Anhand von drei Schlüsselfragen möchte ich zeigen, warum Text-to-Speech für Medienhäuser ein essenzielles Engagement-Tool ist und warum jeder Nachrichtenartikel heutzutage einen Audio-Button haben sollte.
Wie natürlich klingt Text-to-Speech heute?
Die Aufmerksamkeit der breiten Öffentlichkeit erlangte Text-to-Speech (kurz TTS) erstmals nach der legendären Keynote von Steve Jobs im Jahre 1984. Bei der Präsentation des ersten Macintosh ließ Jobs diesen sich selbst und seinen Schöpfer vorstellen. Seitdem ist die Entwicklung synthetischer Stimmen rasant fortgeschritten und hat ihren vermeintlichen Höhepunkt in der Einführung von Smart Speakern, wie Amazon Alexa oder Google Assistant, gefunden. Jetzt können Mensch und Maschine endlich miteinander kommunizieren.
Aber, tun wir das wirklich? Können wir generell zufrieden mit der Hilfestellung sein, die Siri oder Alexa uns heute bieten? Vertrauen wir ihnen all das an, was wir vorher am Computer oder Smartphone selbst erledigt haben? Also auch Aufgaben, die das Einstellen der Alarmfunktion oder das Öffnen einer Playlist übersteigen? Konzerttickets bestellen zum Beispiel. Oder eine Pizza zum Mitnehmen? Welche Route ist die beste zur Umgehung des Staus, um rechtzeitig anzukommen? Siri, Alexa oder Googles Assistant haben uns das Versprechen dieser Interaktion gegeben, aber nie gehalten. Fakt ist: Die Technologie ist einfach noch nicht ausgereift. Von der vorgefertigten Antwort bis hin zu einem echten Austausch ist es noch ein weiter Weg.
Aber was ist mit der Qualität der künstlichen Stimmen? Lassen wir uns längere Texte von unserem Mac vorlesen? Denn der Macintosh besitzt diese Funktion ja nun schon seit 37 Jahren. Haben Sie sich schon einmal einen Nachrichtenartikel vorlesen lassen? Oder ein ganzes Buch? Woran liegt es, dass wir Stunden mit Radio verbringen, uns Podcasts oder sogar ganze Hörbücher vorlesen lassen – doch, wenn synthetische Stimmen ins Spiel kommen, längere Interaktion vermeiden? Wir lassen uns von Google Maps gern an unser Ziel bringen, möchten aber keiner Maschine zuhören, die uns ein ganzes Audiobuch vorliest.
Die Qualität ist entscheidend.
Denn die künstlichen Stimmen, die wir kennen, klingen – nun ja, künstlich. Doch überraschend ist, wie gut eine synthetische Stimme sich anhören kann. Historisch bedingt ist die Technologie in der englischen Sprache am weitesten, da die meisten linguistischen Datenmodelle darauf basierten. Der Qualitätsunterschied einzelner Anbieter wird also vor allem im Deutschen oder anderen lokalisierten Sprachen deutlich. Die Antwort auf diese Frage ist also recht simpel: Fokussierte Anbieter guter TTS-Technologie erschaffen schon heute ein Audioerlebnis, das viel natürlicher klingt, als man vermuten würde.
Welchen Einfluss hat Text-to-Speech auf das Konsumverhalten?
Welche Nachrichtenblätter werden gelesen? Wie oft wird die App gewechselt und werden Artikel wirklich immer bis zum Ende gelesen? Fakt ist, die meisten User springen als sogenannte „Fly-bys“ zwischen Websites und Apps hin und her. In Zeiten des „Information-Overloads“ sind wir diesem – getriggert durch Social Media – regelrecht verfallen: Verheißende Titel werden angeklickt und nach kurzem Überfliegen des Haupttextes wieder verlassen. Diese Fly-bys zu loyalen NutzerInnen zu machen, ist eine der signifikanten Herausforderungen der Verlagsbranche. Laut dem Reuters Institute for the Study of Journalism liegt das größte Umsatzpotenzial für Verlage im Wachstum der Abonnentenzahlen (52%), gefolgt von Display Advertising (27%).
Den richtigen Inhalt zur richtigen Zeit an den richtigen User liefern – dies sind die Schlüsselpunkte für eine positive Nutzererfahrung, welche wiederum essenziell für das Abschließen eines Premiumangebots ist.
Doch was ist der „richtige Zeitpunkt“? Wir alle haben nie genug Zeit und sind getrieben von Ablenkungen beim Lesen, sei es von einer E-Mail oder einer Push Notification auf dem Smartphone. Um den richtigen Zeitpunkt nicht zu verpassen, bietet der Einsatz von Text-to-Speech diese positive Erfahrung: Während der Artikel gehört wird, können E-Mails weitergeschrieben oder eine Push-Nachricht beantwortet werden. Und all das ohne Bouncing, also ohne das Verlassen der Webseite.
Wie groß ist die Nachfrage nach Audioinhalten?
2020 war das Jahr, das ganz im Zeichen von Audio stand: Erstmals lag die Nutzung von Audioangeboten über der Nutzung von Social Media, Gaming und Video. Podcasts spielen dabei natürlich eine wichtige Rolle und die Nachfrage nach Audioangeboten ist so immens, dass die führende Musikstreaming-Plattform Spotify eine Vielzahl an Akquisitionen angekündigt hat, um die Dominanz auch in diesem Bereich auszubauen. Laut Spotify CEO Daniel Ek haben Podcasts einen enormen Einfluss auf die Nutzerbindung und somit auf den „Lifetime-Value“, also den Wert eines Nutzers über einen gewissen Zeitraum hinweg.
Allerdings gibt es ein Problem mit Podcasts: Deren Produktion ist sehr kostenaufwendig.
Text-to-Speech gibt Publishern die Möglichkeit, Audioinhalte für alle Artikel auf Knopfdruck zu erstellen. Dabei müssen keine zusätzlichen Ressourcen innerhalb der Redaktion eingesetzt werden, denn die Inhalte stehen ja bereits in Textform zur Verfügung. Und diese Inhalte können dann immer genau dort konsumiert werden, wo es keine Möglichkeit zur Interaktion mit Texten gibt: auf dem Weg zur Arbeit, beim Sport oder beim Kochen.
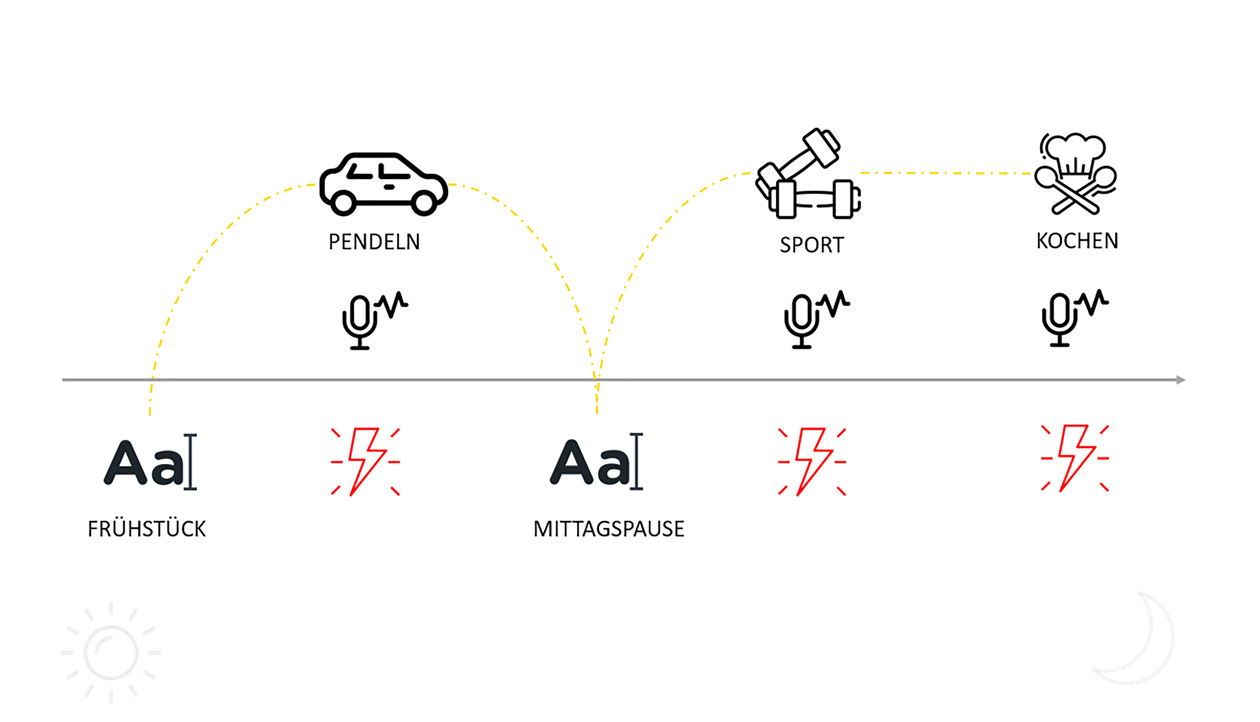
Die Customer Journey von LeserInnen zeigt, dass der Einsatz von Text-to-Speech zusätzliche Touchpoints schafft, die den Grundstein für die Bindung von NutzerInnen und deren Loyalität legen.
Den ausführlichen Blogpost von BotTalk finden Sie in englischer Sprache hier.
Notizblock:
LinkedIn: Andrey Esaulov
Web: https://bottalk.io/


