
Künstliche Intelligenz macht die redaktionelle Arbeit effizienter. Mit unserem neuen KI-Rechercheassistenten kann das gesamte dpa-Archiv bis einschließlich 2020 anhand einfacher Sprachbefehle durchsucht werden. So wie Journalistinnen und Journalisten es von KI-Anbietern gewohnt sind. Damit die Ergebnisse immer besser werden, überprüfen wir den Output systematisch zusammen mit unserem Partner DFKI. Welche Metriken wir dabei anwenden, zeigt dieser Beitrag.
Die Ergebnisse unseres Rechercheassistenten – einem „Retrieval-Augmented Generation“-System (RAG), das in Kooperation mit dem US-amerikanischen KI-Unternehmen You.com entwickelt wurde – schaffen den Einstieg in die Nachrichtenrecherche. Journalistinnen und Journalisten erhalten Zusammenfassungen, relevante Zitate und die passenden Original-Dokumente zu den Informationen, die sie interessieren. Wie wir bei der Entwicklung konkret vorgegangen sind, könnt ihr hier nachlesen.
Besonders wichtig war uns, dass sich das System ausschließlich auf unsere dpa-Daten bezieht – und dabei möglichst wenig halluziniert. Daher wurde bereits früh eine redaktionelle Testgruppe eingebunden, die den Retrieval-Prozess – also die Auswahl der passenden Dokumente – sowie die Antworten des Rechercheassistenten sorgfältig prüft. So erhält You.com regelmäßig direktes Feedback unserer Nutzerinnen und Nutzer.

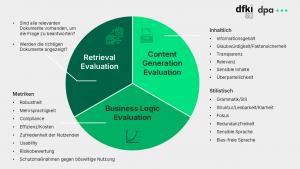
Dieser Feedback-Prozess ist sehr wichtig, um die Qualität des Systems zu gewährleisten – gegenüber den dpa-Redakteurinnen und -Redakteuren wie auch unseren Kundinnen und Kunden. Auch deshalb haben wir einen zweiten starken Partner an unserer Seite. Das Deutsche Forschungszentrum für Künstliche Intelligenz (DFKI) ist seit Jahren Pionier der KI-Forschung in Deutschland und verbindet Wissenschaft und wirtschaftliche Praxis. Gemeinsam mit dem Team um Senior Researcher Leonhard Hennig haben wir in zwei Präsenzworkshops drei Kernbereiche definiert, um die Ergebnisse unseres RAG-Systems systematisch zu evaluieren: Retrieval Evaluation, Content Generation Evaluation und Business Logic Evaluation. Jeder Bereich hat spezifische Fragestellungen und Metriken, die wir in diesem Blogbeitrag skizzieren. Mit dem DFKI haben wir uns auf die Evaluation des Retrieval-Prozesses sowie auf die qualitative Evaluation der Ergebnisse fokussiert.
Retrieval Evaluation: Sind die richtigen Dokumente dabei?
RAG-Systeme erweitern die Funktion großer Sprachmodelle (LLMs), indem sie gezielt vorab festgelegte Wissensquellen abrufen. Unternehmen haben dadurch die Kontrolle über die Textausgabe und die Antwortgenerierung bleibt durch die Verlinkung der Quellen für die Nutzerinnen und Nutzer transparent. Dennoch muss auch bei RAG-Systemen zunächst überprüft werden, ob alle relevanten Informationen vorhanden sind, um die gestellte Frage zu beantworten. Gleichzeitig ist zu prüfen, ob der Retrieval-Prozess der Dokumente korrekt abläuft und die Quellen tatsächlich auf die abgefragten Informationen abzielen.
Um dies zu bewerten, empfiehlt sich eine manuelle Überprüfung, binär mit einer klassischen Daumen-hoch- oder Daumen-runter-Funktion. Für ein Set an Suchanfragen wird geprüft, ob die Top-10 der angezeigten Dokumente passend und präzise sind. Dabei sollten die Suchanfragen möglichst vielfältig sein, um verschiedene Fragetypen für die unterschiedlichen Redaktionen abzudecken. Unsere Erfahrungen haben gezeigt, dass Redakteurinnen und Redakteure unterschiedlicher Ressorts auch unterschiedliche Anforderungen an unseren Rechercheassistenten mitbringen. Alternativ könnten die Dokumente auch mit einer menschlich erstellten Referenzantwort verglichen werden, was jedoch aufwändiger, weniger standardisiert und dadurch quantitativ weniger aussagekräftig ist.
Content Generation Evaluation: Sind die Antworten qualitativ hochwertig?
Im Anschluss an den Retrieval-Prozess generiert das Sprachmodell Antworten basierend auf den abgerufenen Dokumenten. Hier stehen sowohl die inhaltliche als auch die sprachliche Qualität der Ergebnisse im Fokus. Inhaltlich sollten die Antworten alle relevanten Aspekte der Frage abdecken und sich ausschließlich auf die abgerufenen Quellen stützen. Gleichzeitig ist sicherzustellen, dass die Antworten faktenbasiert und frei von Verzerrungen oder sensiblen Inhalten sind. Hierin liegt die Stärke des dpa-KI-Rechercheassistenten, denn die zugrundeliegenden Archiv- und Echtzeitdaten erfüllen diese Voraussetzungen.
Auf sprachlicher Ebene wird geprüft, ob die Antworten grammatikalisch korrekt, logisch strukturiert sowie klar und überparteilich formuliert sind. Wiederholungen oder ein unpassender Stil sollten vermieden werden. Hier ist es hilfreich, alle generierten Inhalte systematisch zu speichern, um später Muster und Schwächen analysieren zu können. Nutzerstudien und gezieltes Feedback tragen dazu bei, die Antworten weiter zu verbessern. Daher ist es wichtig, von Beginn an eine Datenbasis aufzubauen und die Ergebnisse der eigenen Suchanfragen zu speichern und abzulegen.
Business Logic Evaluation: Erfüllt das System die Anforderungen des eigenen Geschäftsmodells?
Neben technischer Präzision muss ein RAG-System auch den geschäftlichen Anforderungen entsprechen. Dazu gehört, dass es die Bedürfnisse der Nutzer erfüllt und dabei den vorgegebenen Geschäftsregeln folgt. Gleichzeitig ist die Effizienz entscheidend: Wie hoch sind die Kosten? Welche Zeitersparnis ergibt sich für die Nutzenden, also für die Redakteurinnen und Redakteure im Newsroom?
Hierbei liegen Metriken wie Robustheit unter verschiedenen Bedingungen, Schlussfolgerungsfähigkeit des Systems, Mehrsprachigkeit und Effizienz zugrunde. Zudem sollte sichergestellt sein, dass das System nicht auf sensible oder überholte Inhalte zugreifen kann, die nicht für die Veröffentlichung bestimmt sind. Im Falle der dpa kann es beispielsweise vorkommen, dass Meldungen zurückgezogen, mit Sperrfristen versehen oder inhaltlich korrigiert werden – diese tauchen in den Ergebnissen des Rechercheassistenten entsprechend nicht auf.
Ganzheitliche Evaluierung für nachhaltigen Erfolg – menschliches Urteilsvermögen bleibt wesentlich
Die Evaluierung eines RAG-Systems erfordert eine umfassende Analyse: vom Abruf relevanter Dokumente über die Qualität der generierten Inhalte bis hin zum Rahmen der eigenen Geschäftstätigkeit. Für die Evaluierung unseres KI-Rechercheassistenten gilt: Im Kern bleibt bei aller Künstlichkeit das menschliche Urteilsvermögen. Regelmäßige Tests und das Sammeln von Daten sind entscheidend, um Schwächen des Systems zu identifizieren und es kontinuierlich zu verbessern. Nur durch diese strukturierte Herangehensweise lässt sich sicherstellen, dass ein RAG-System den Anforderungen seines Nutzungsumfeldes gerecht wird – und die könnten im Journalismus mit Blick auf faktenbasierte, geprüfte Informationen nicht hoch genug sein.
Ihr habt Interesse an einem eigenen RAG-System oder Fragen zu unserem KI-Rechercheassistenten? Kontaktiert uns gerne, unter KI@dpa.com.
„dpa-Recherche“: In fünf Schritten zum eigenen RAG
KI-Recherche für den Newsroom: Wie wir gemeinsam mit You.com Redaktionen effizienter machen



